通过以下代码你可以获取著名的金融数据平台Tushare的股票日线交易数据,存入数据表
代码的优势在于:
- 1.可以自定义数据的获取的范围,主要通过Define time period的日期参数可调整实现
- 2.可以获取自己想要的股票数据,主要通过数据表stock_basic来确定ts_code范围(这里附加的前提就是你从Tushare获取基础信息时要按照自己的需求过滤不需要的数据,例如:不考虑ST、和自己没有交易资格的北交所数据等)
- 3.Rate limiting和time.sleep进一步增强了再数据获取时的请求限制,并避免了因代码逻辑不严谨导致的数据请求丢失
- 4.同时代码还具有batch_size的分批请求和tqdm的数据请求进度,以及数据是否已经存在的校验判断Function to check if data already exists
import pandas as pd
from sqlalchemy import create_engine
from sqlalchemy.orm import sessionmaker
from tqdm import tqdm
import concurrent.futures
import tushare as ts
from threading import Semaphore, Timer
import time
# Initialize tushare
ts.set_token('your_token')
pro = ts.pro_api()
# Create database connection
engine = create_engine('mysql+pymysql://username:password@localhost:3306/stock')
Session = sessionmaker(bind=engine)
session = Session()
# Get stock list with list_date
query = "SELECT ts_code, list_date FROM stock.stock_basic"
stock_list = pd.read_sql(query, engine)
# Define time period
default_start_date = '20240802'
end_date = '20240802'
# Rate limiting
CALLS = 1500 # 每分钟最大请求次数
RATE_LIMIT = 60 # seconds
BATCH_SIZE = 1000 # 每次请求的股票代码数量
# Create a semaphore to limit the number of API calls
semaphore = Semaphore(CALLS)
# Function to periodically release the semaphore
def release_semaphore():
for _ in range(CALLS):
semaphore.release()
# Start timer to release semaphore every minute
Timer(RATE_LIMIT, release_semaphore, []).start()
# Function to check if data already exists
def data_exists(ts_code, trade_date):
query = f"SELECT 1 FROM daily WHERE ts_code='{ts_code}' AND trade_date='{trade_date}' LIMIT 1"
result = pd.read_sql(query, engine)
return not result.empty
# Define retry decorator
def retry():
def decorator(func):
def wrapper(*args, **kwargs):
for _ in range(10):
try:
result = func(*args, **kwargs)
return result
except Exception as e:
print(f"Error occurred: {e}. Retrying...")
time.sleep(30)
raise Exception("Maximum retries exceeded. Function failed.")
return wrapper
return decorator
# Define function to fetch and insert stock data
@retry()
def fetch_and_insert_stock_data(ts_code, list_date, end_date, engine):
# Determine start_date based on list_date
start_date = max(list_date.replace('-', ''), default_start_date)
# Check if data already exists
if data_exists(ts_code, end_date):
return f"Data already exists for {ts_code} on {end_date}"
# Wait on semaphore to respect rate limiting
semaphore.acquire()
try:
# Fetch data from tushare
stock_data = pro.daily(ts_code=ts_code, start_date=start_date, end_date=end_date)
# If data is not empty, insert it into the database
if not stock_data.empty:
# Map API fields to database fields
stock_data.rename(columns={'vol': 'volume'}, inplace=True)
stock_data.to_sql('daily', engine, if_exists='append', index=False, method='multi')
return ts_code
finally:
# Release the semaphore after the operation
semaphore.release()
# Initialize progress bar
total_stocks = len(stock_list)
pbar = tqdm(total=total_stocks, desc="Fetching stock data")
def process_batch(batch):
with concurrent.futures.ThreadPoolExecutor() as executor:
futures = {
executor.submit(fetch_and_insert_stock_data, row['ts_code'], row['list_date'], end_date, engine): row['ts_code']
for index, row in batch.iterrows()
}
for future in concurrent.futures.as_completed(futures):
ts_code = futures[future]
try:
data = future.result()
pbar.update(1)
except Exception as exc:
print(f'{ts_code} generated an exception: {exc}')
# Process stocks in batches
batch_size = BATCH_SIZE
for i in range(0, total_stocks, batch_size):
batch = stock_list.iloc[i:i + batch_size]
process_batch(batch)
time.sleep(60) # Wait to respect rate limits
# Close progress bar
pbar.close()
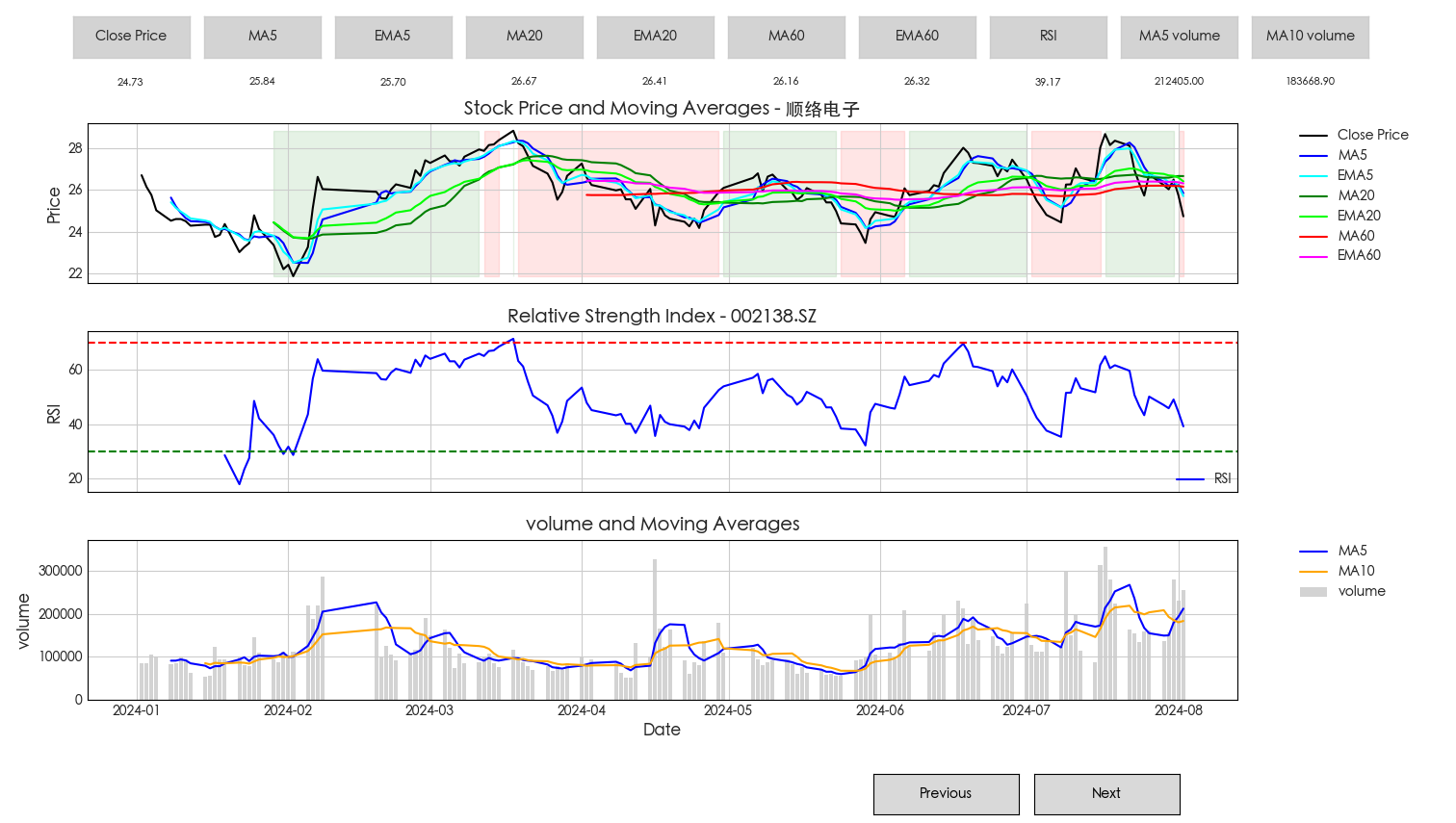
股市交易,学会使用数据进行市场行情研究和是否买入/卖出判断,要比通过有心人捏造并通过媒体报道的消息更具有参考意义。